
A web scraper is a tool that allows us to select and transform websites’ data into a structured database. Here are a few of my favorite use-cases for a web scraper:
- 📰 Scrape news websites to apply custom analysis and curation (manual or automatic), provide better-targeted news to your audience
- 🏚 Scrape real estate listings — businesses are using web scraping to gather listed properties
- 🔎 Scrape products/product reviews from retailer or manufacturer websites to show on your site, provide specs/price comparison
- 💌 Gathering email addresses for lead generation
As a simple example — we’ll learn to scrape the front page of The Economist to fetch titles and their respective URLs. You can select and aggregate data, perform custom analysis, store it in Airtable, Google sheets, or share it with your team inside Slack. The possibilities are infinite!
Please remember to respect the policies around web crawlers of any sites you scrape.
Now Let’s get started!
Part 1: Setup your Website Crawler.Query API from Autocode
Follow this link to set up your crawler API on Autocode: autocode.stdlib.com/new/?workflow=crawler%2Fquery%2Fselectors
You will be prompted to sign in or create a FREE account. If you have a Standard Library account click Already Registered and sign in using your Standard Library credentials.
You will be re-directed to Autocodes Maker Mode.
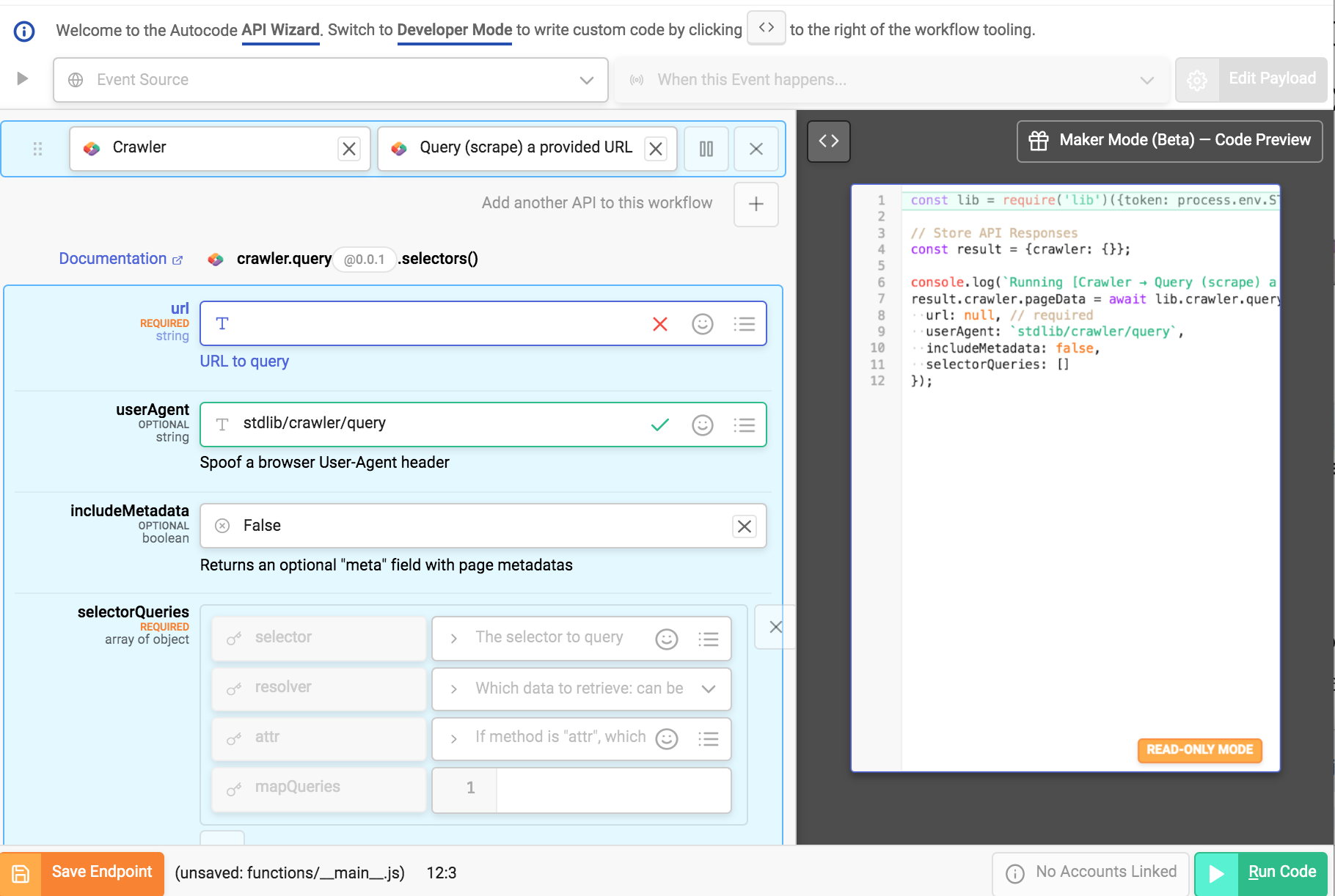
Maker Mode is a workflow builder like Zapier, IFTTT, and other Automation tools, with some important differences. Maker Mode generates code and it’s completely accessible for editing.
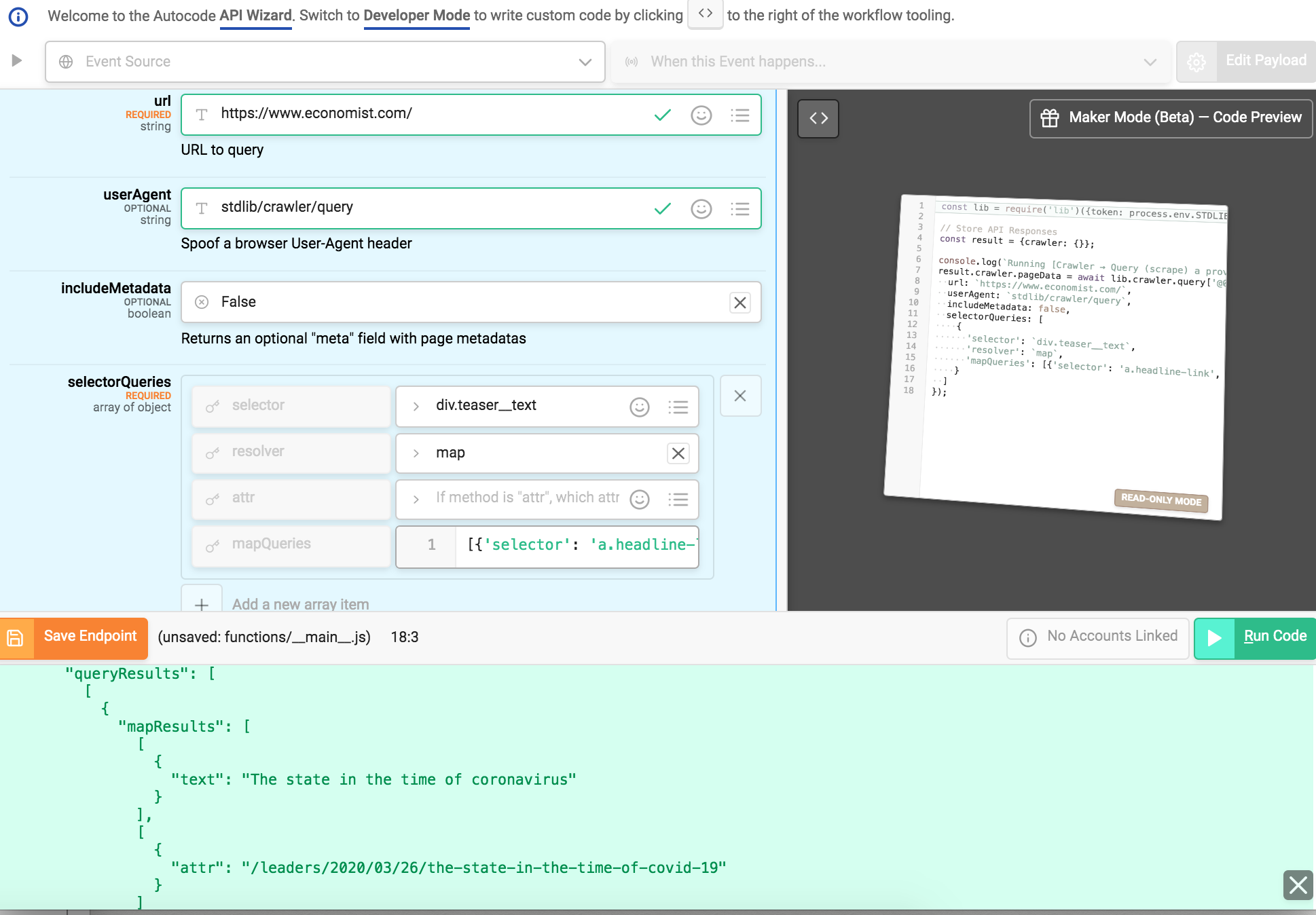
Fill the following settings;
- url is https://www.economist.com/ (URL to the website we’ll crawl)
- userAgent is stdlib/crawler/query (this is the default)
- includeMetadata is False (if True, will return additional metadata in a meta field in the response)
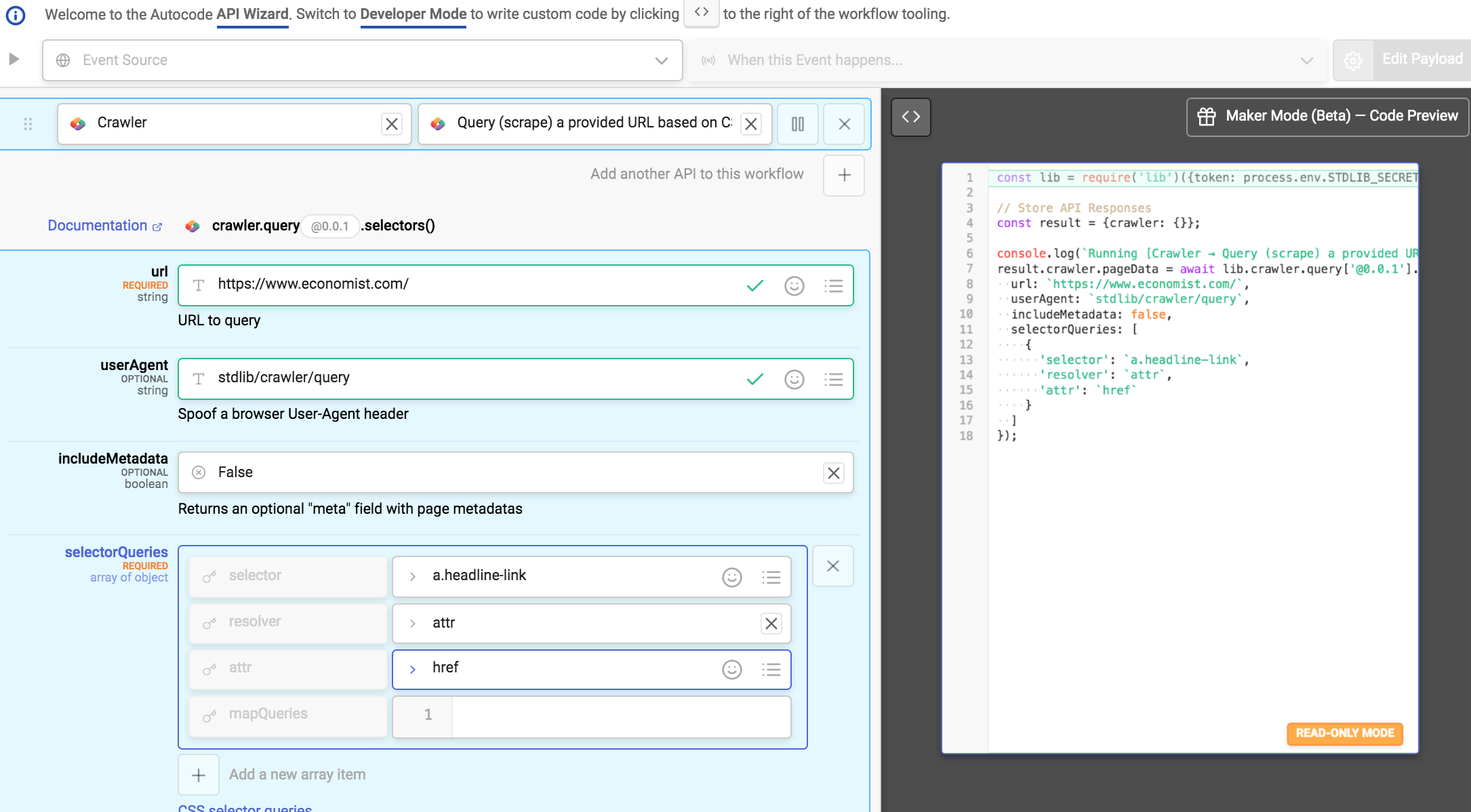
- selectorQueries is an array with one object, the values being {"selector":"a.headline-link","resolver":"text"}
When you input these settings notice the code generated on the right.
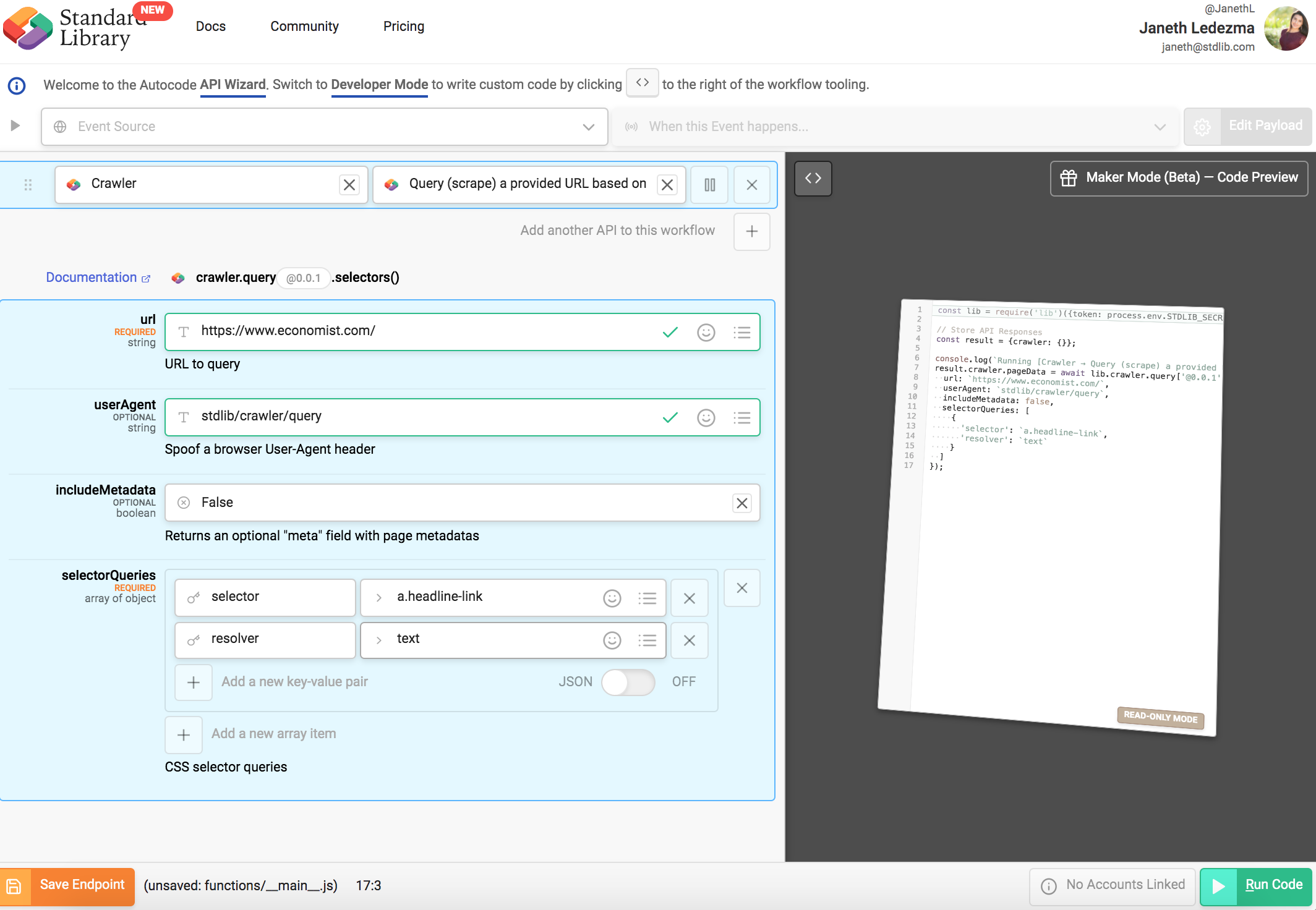
Select the green “Run Code” button to test run your code.

Within seconds you should see a list of titles from the front page of The Economist.
🤓 How it Works
The web scraper makes a simple GET request to a URL, and runs a series of queries on the resulting page and returns it to you. It uses cheerio DOM (Document Object Model) processor, enabling us to use CSS-selectors to grab data from the page. CSS selectors are patterns used to select the element(s) you want to organize.
How to Query any Website Using CSS Selectors
Web pages are written in markup languages such as HTML. An HTML element is one component of an HTML document or web page. Elements define the way information is displayed to the human eye on the browser- information such as images, multimedia, text, style sheets, scripts etc.
For this example, we used the “.class1.class2” selector ( “a.headline-link” ) to fetch the titles of all hyperlinks from all elements on the front page of The Economist.
If you are wondering how to find the names of the elements that make up a website — allow me to show you!
Fire up Google Chrome and type in our The Economist URL address https://www.economist.com/. Then right-click on the title of any article and select “inspect.” This will open the Web Console on Google Chrome. Or you can use command key (⌘) + option key (⌥ ) + J key.
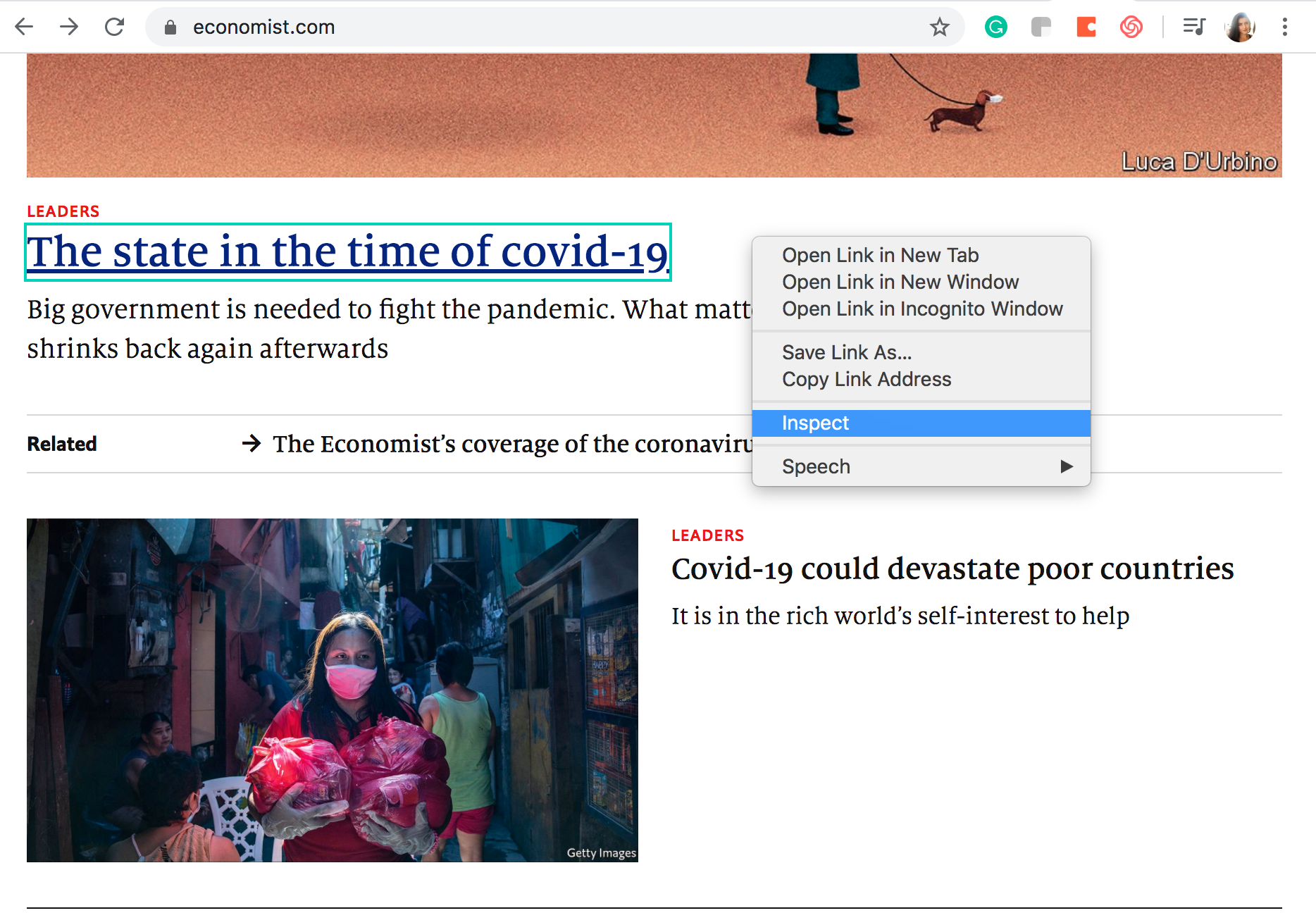
The web-developer console will open to the right of your screen.
Select the cursor located in the developer console menu or command key (⌘) + option key (⌥ ) + C.
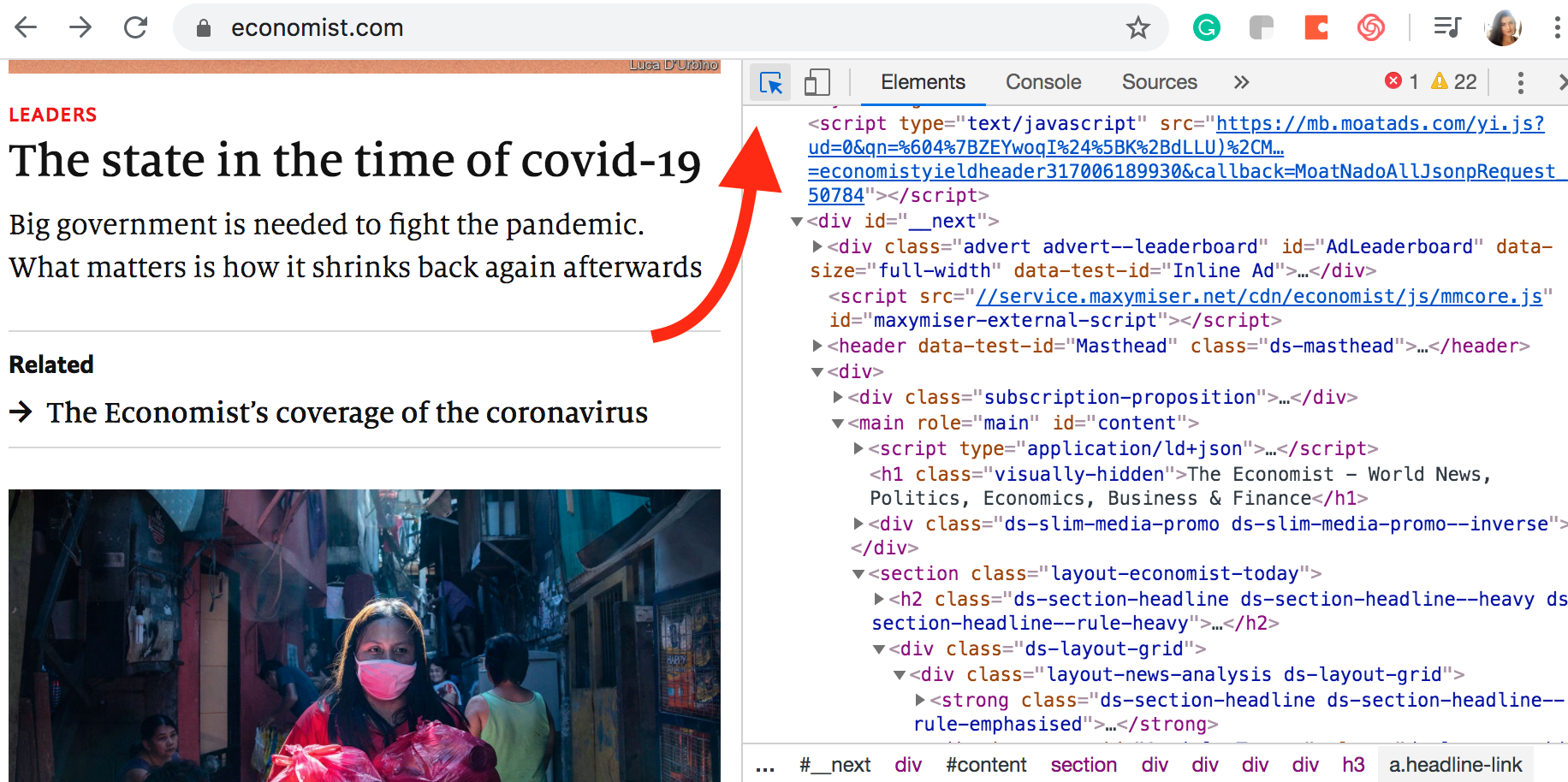
This will enable element highlighting so that whenever you hover your cursor over the website you can quickly identify elements on the developer console.
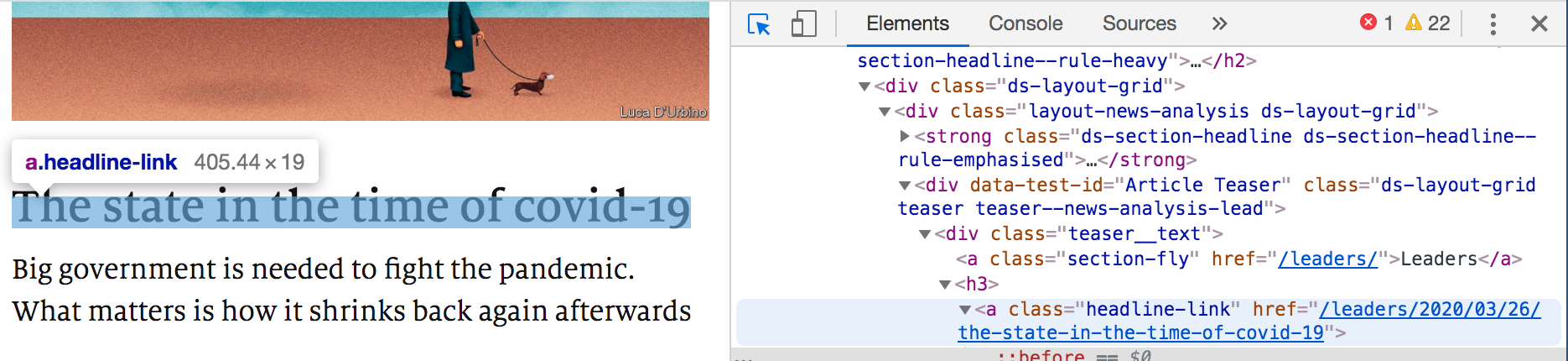
Notice that when you selected the title of a link, a section on the console is also highlighted. The highlighted element has “class” defined as “headline-link.”
And now you know how we queried for the title of a link! 🙌🏼
Web Scraping, Next Steps
You might be wondering how to customize this further. First, the resolver object attribute can take one of four values: text, html, attr and map.
- text returns the element text
- html returns the element HTML
- attr returns an HTML attribute of the element, you must add an additional attr key with a value like "attr": "href"
- map returns a nested CSS selector query, this requires an additional mapQueries attribute expecting another array of selectorQueries
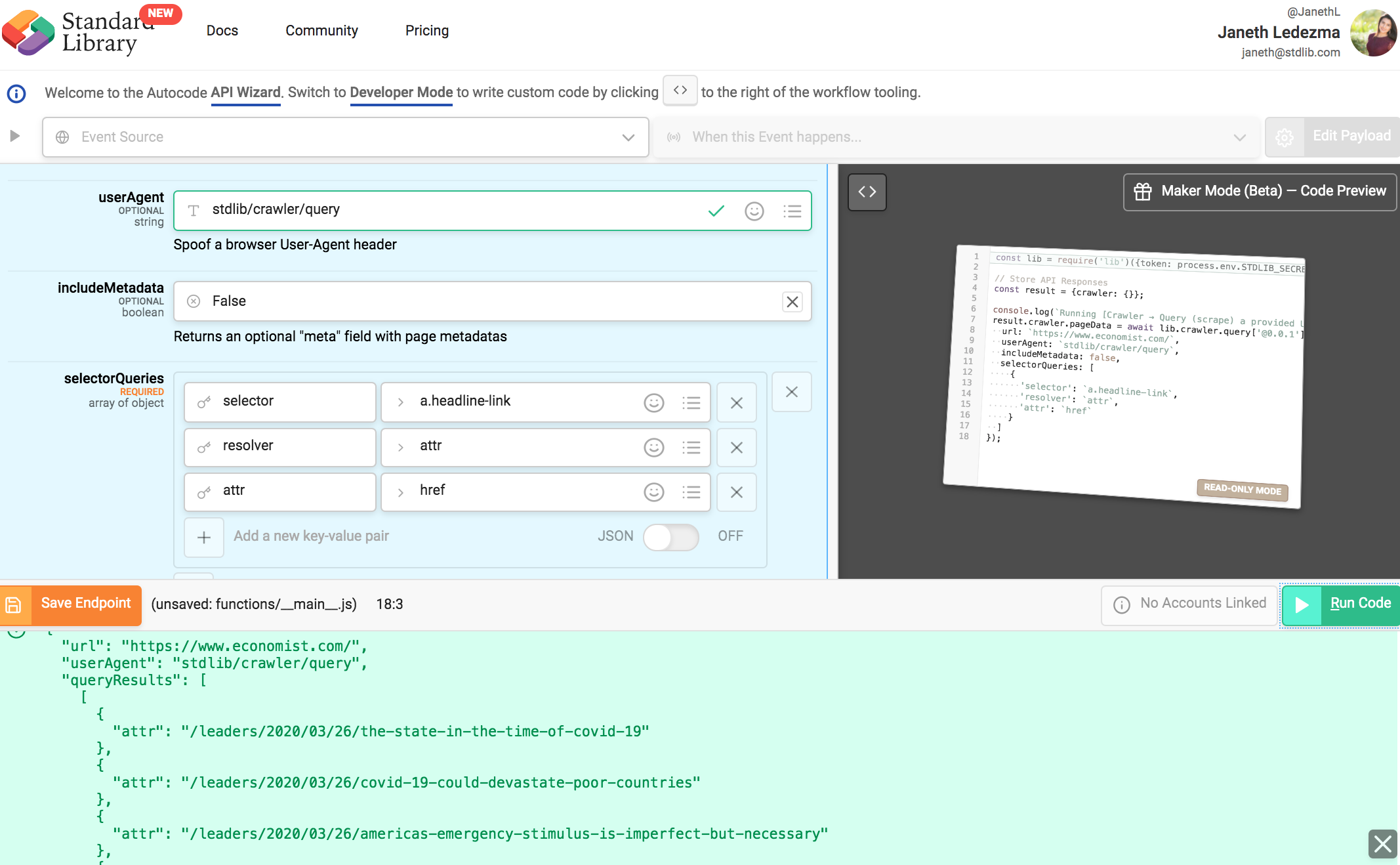
Using "resolver": "attr" to Query Links
To query titles links, we’ll need to set resolver to take an attr value and add an additional attr key with value href.

We would expect a response that looks like this when running the code:
Using "resolver": "map" to Query Title and URL
We can use map to make subqueries (called mapQueries) against a selector to parse data in parallel. For example, if we want to combine the above two queries (get both title and URL simultaneously)...
Input the following setting for your selectorQueries:
selector: a.div.teaser__text
resolver: map
mapQueries: [ { 'selector': 'a.headline-link', 'resolver': 'text' }, { 'selector': 'a.headline-link', 'resolver': 'attr', 'attr': 'href' } ]
This query is looking for any element <div class="teaser__text"> and then running another query against it with mapQueries.
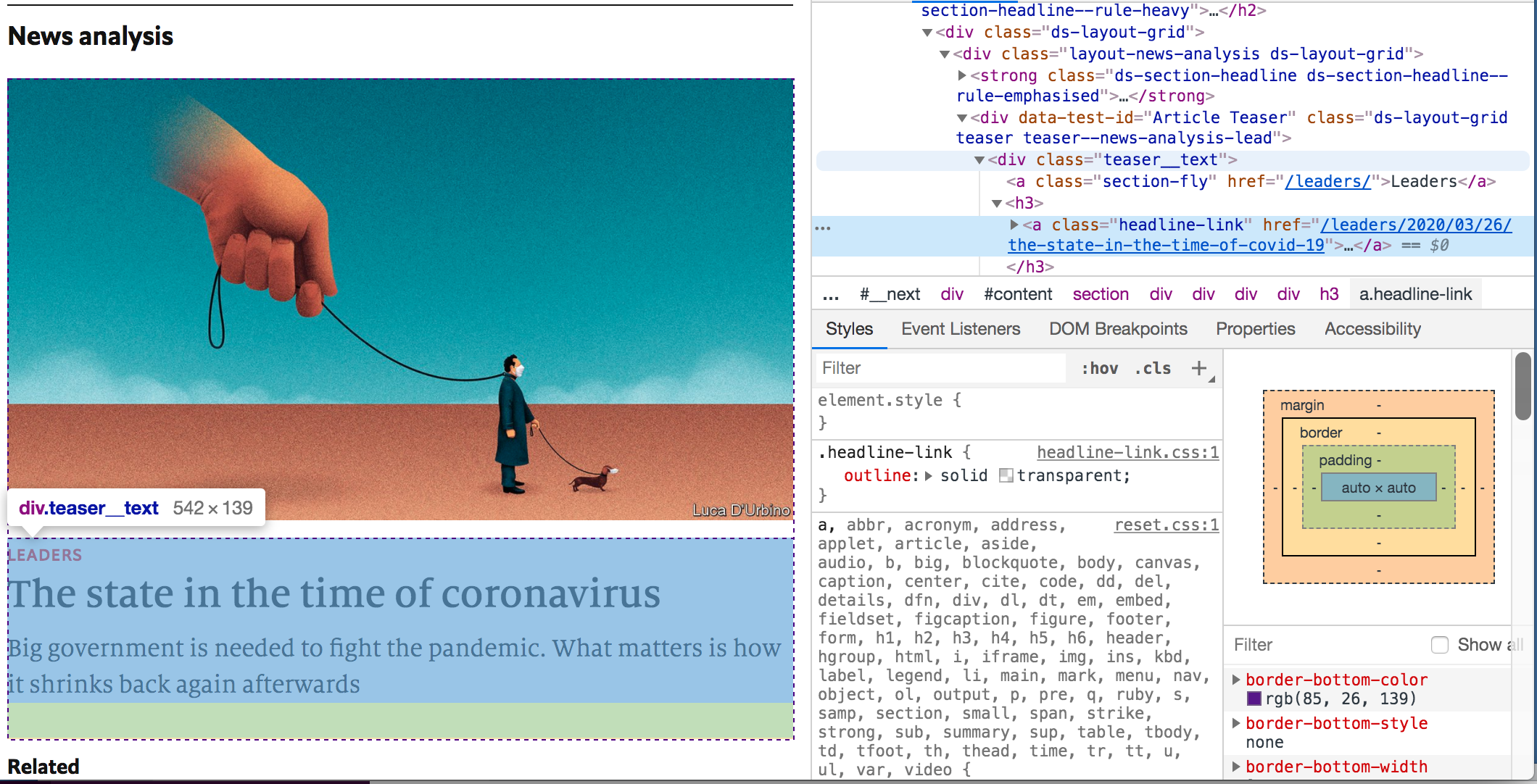
And our result should return titles and links.
🙌🏼 That’s It, and Thank You!
In the next tutorial, we will set up a Slack app that uses this crawler.api to query websites using a Slack slash command and posts results in a channel. Stay tuned!
I would love for you to comment here, e-mail me at Janeth [at] stdlib [dot] com, or follow Standard Library on Twitter, @StandardLibrary. Let me know if you’ve built anything exciting that you would like Standard Library team to feature or share — I’d love to help!
Janeth Ledezma is a Developer Advocate for Standard Library. Follow her journey with Standard Library on Twitter @ms_ledezma.
.png)
