
PDF is here to stay. In today’s work environment, PDF became ubiquitous as a digital replacement for paper and holds all kind of important business data. But what are the options if you want to extract data from PDF documents? Manually rekeying PDF data is often the first reflex but fails most of the time for a variety of reasons. In this article we talk about PDF data extraction solutions (PDF Parser) and how to eliminate manual data entry from your workflow.
The case for extracting data from PDF documents
Since PDF was first introduced in the early 90’s, the Portable Document Format (PDF) saw tremendous adoption rates and became ubiquitous in today’s work environment. PDF files are the go-to solution for exchanging business data, internally as well as with trading partners. Some popular use-cases for PDF documents in fields like supply chain, procurement and business administration are:
- Invoices
- Purchase Orders
- Shipping Notes
- Reports
- Presentations
- Price & Product Lists
- HR Forms
- …
All documents types mentioned above have one thing in common: They all are used to transfer important business data from point A to point B.
So far so good. There is however a catch … PDF is basically just a replacement for paper.
In other words, data stored in PDF documents is basically as accessible as data written on a piece of paper. This becomes a problem though whenever you need to access the data stored inside your documents in a convenient way. Which raises for example the question how to extract data from PDF to Excel files?
The default reflex is to manually re-key data from PDF files or performing a copy & paste. Obviously, manual data entry is a tedious, error-prone and costly method and should be avoided by all means. Further below we present you different approaches on how to extract data from a PDF file. But first lets dive into why PDF data extraction can be a challenging task.
Why is it challenging to extract data from PDF files?
There are several reasons why extracting data from PDF can be challenging, ranging from technical issues to practical workflow obstacles.
For starters, a lot of PDF files are actually scanned images. While those documents are easily readable for humans, computers are not capable to understand the scanned image text without first applying a method called Optical Character Recognition (OCR).
Once your documents went through a OCR PDF Scanner and actually contain text data (and not just images), it’s possible to manually copy & paste parts of the text. Obviously, this method is tedious, error-prone and not scalable. Opening each PDF document individually, locating the text you are after, then selecting the text and copying to another software just takes way too much time.
How to extract data from a PDF?
Manually re-keying data from a handful of PDF documents
Let’s be honest. If you only have a couple of PDF documents, the fastest route to success can be manual copy & paste. The process is simple: Open every single document, select the text you want to extract, copy & paste to where you need the data.
Even when you want to extract table data, selecting the table with your mousepointer and pasting the data into Excel will give you decent results in a lot of cases. You can also use a free tool called Tabula to extract table data from PDF files. Tabula will return a spreadsheet file which you probably need to post-process manually. Tabula does not include an OCR engines, but it’s definitely a good starting point if you deal with native PDF files (not scans).
Outsourcing manual data entry
Outsourcing data entry is a huge business. There are literally thousands of data entry providers out there you can hire. In order to offer fast and cheap services, those companies hire armies of data entry clerks in low-income countries which then do the heavy-lifting. Obviously, data entry providers also use advanced technology to speed up the process, the overall workflow is however basically the same than the one described above: opening every single document, selecting the right text area and putting the data inside a database or a spreadsheet.
Outsourcing manual data entry comes with a lot of overhead. Finding the right provider, agreeing on terms and explain your specific use-case makes economically only sense if you need to process high volumes of documents. And still, it’s likely much more efficient to let our automated software do the job we do with our email parser or PDF Docparser.
Fully automated PDF data extraction software
Automated PDF data extraction solutions come in different flavours, ranging from simple OCR tools to enterprise ready document processing and workflow automation platforms. Most systems share however a similar workflow:
- Assemble batches of samples documents which acts as training data
- Train the system for each type of document you want to process
- Set up a process to automatically fetch documents, process them and dispatch the data
Most advanced solutions use a combination of different techniques to train the data extraction system. A simple method is for example Zonal OCR where the user simply defines specific locations inside the document with a point & click system. More advanced techniques are based on regular expressions and pattern recognition.
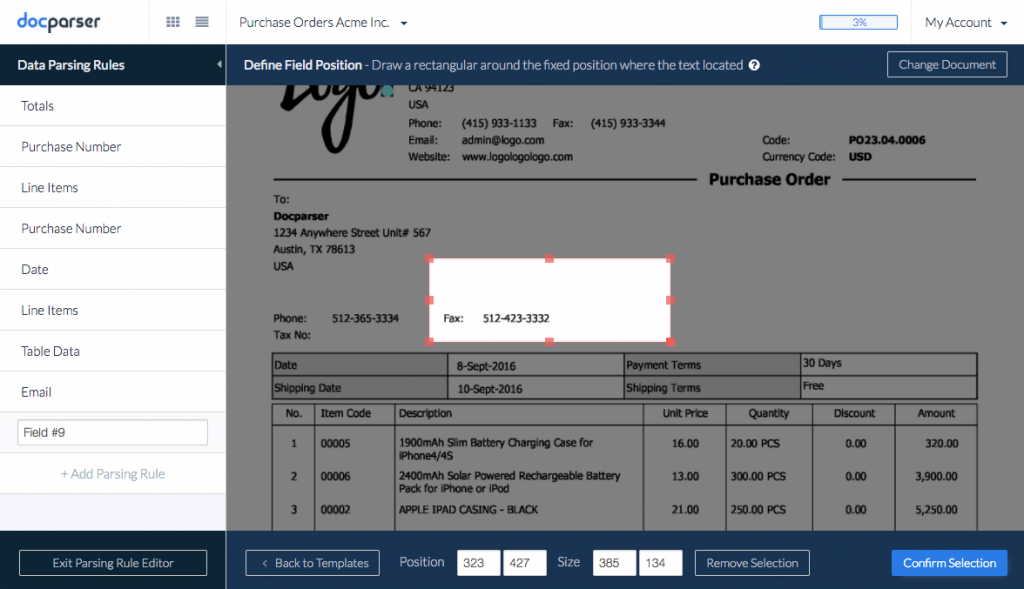
After the initial training period, document data extraction systems offer a fast, reliable and secure solution to automatically convert PDF documents into structured data. Especially when dealing with many documents of the same type (Invoices, Purchase Orders, Shipping Notes, …), using a PDF Parser is a viable solution.
At Docparser, we offer a powerful, yet easy-to-use set of tools to extract data from PDF files. Our solution was designed for the modern cloud stack and you can automatically fetch documents from various sources, extract specific data fields and dispatch the parsed data in real-time. Have a look at our screencast below which gives you a good idea of how Docparser works.
We hope you got a better picture on the different options for extracting data from PDF documents. Please don’t hesitate to leave a comment or to reach out to us by email.
.png)
